Cloud Infrastructure Technologies
The below notes are a mix of self-learning from internet and free Linux Foundation course Introduction to DevOps and Site Reliability Engineering (LFS162x) and Introduction to Cloud Infrastructure Technologies (LFS151x).
Initial cloud concepts
Cloud computing
Cloud computing can be defined as
Computation performed on a remote machine.
The remote machine can be present on the company premises in another branch/location or provided by cloud platform providers such as Google Cloud/AWS Cloud/Microsoft Azure/DigitalOcean.
NIST-800-145 defines cloud computing as a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction.
As the infrastructure (remote machines) are present remotely at someone else’s premises, the end-users can benefit from speed and agility, cost, easy access to resources, maintenance, multi-tenancy, and reliability.
Users can deploy cloud in different scenarios:
Public cloud: Cloud platform such as Google Cloud/AWS Cloud/Microsoft Azure/DigitalOcean
Private cloud: Cloud hosted internally or externally and managed by internal teams such as Openstack
Hybrid cloud: Combination of public and private
There could be different service models such as
Infrastructure as a Service (IaaS)
Platform as a Service (PaaS)
Software as a Service (SaaS)
Virtualization
Now, imagine that an administrator wants to deploy ten web servers. There are multiple options:
run them on different bare-metal machines (10 desktops with standard specs such as 8GB RAM, 40 GB HDD/SDD, 4-Core CPU) or
run them on ten virtual machines running on one bare-metal machine (one server with high specs such as 64/128 GB RAM, 2 TB SSD, multi-core CPUs) or
run them on containers
Officially, Wikipedia defines virtualization as an act of creating a virtual (rather than actual) version of something, including virtual computer hardware platforms, operating systems, storage devices, and computer resources
Users can achieve virtualization at different hardware and software layers, such as the Central Processing Unit (CPU), storage (disk), memory (RAM), filesystems.
To perform the virtualization, we can use a Hypervisor.
Hypervisor
Hypervisor is defined as software that performs virtualization.
Wikipedia defines hypervisor (or virtual machine monitor, VMM, virtualizer) as a kind of emulator; it is computer software, firmware, or hardware that creates and runs virtual machines.
There are two types of hypervisors:
Type-1, native or bare-metal hypervisors
Type-2, hosted hypervisors
Type-1, native or bare-metal hypervisors
Hypervisors that run directly on the host’s hardware to control the hardware and manage guest operating systems are called bare-metal hypervisors or Type-1 hypervisors.
Examples are Microsoft Hyper-V, VMware ESXi, Xen, Nutanix AHV, XCP-ng, Oracle VM Server for SPARC, Oracle VM Server for x86, POWER Hypervisor, and QNX Hypervisor.
Type-2 or hosted hypervisors
Type-2 hypervisor (hosted) runs on top of the host’s OS, mainly used by end-users. For instance, running a Windows/Linux OS and running a hypervisor on top of it.
Examples include VirtualBox, VMware Player, VMware Workstation, Parallels Desktop for Mac.
Type-1/2 Hypervisor Example: Linux KVM
Linux-KVM defines KVM (for Kernel-based Virtual Machine) as a full virtualization solution for Linux on x86 hardware containing virtualization extensions (Intel VT or AMD-V).
KVM is a loadable virtualization module of the Linux kernel. It converts the kernel into a hypervisor capable of managing guest Virtual Machines.
Debian has provided instructions to install KVM on Debian
Manage KVM VMs
There are multiple options to manage KVM Virtual Machines
virsh: A minimal shell around libvirt for managing VMs.
VMM/Virtual Machine Manager: Also known as virt-manager. A desktop user interface for managing virtual machines.
Cloudstack: Cloudstack is an open-source project that enables the deployment, management, and configuration of multi-tier and multi-tenant infrastructure cloud services using Xen, KVM, and VMware hypervisors.
Proxmox VE: Proxmox Virtual Environment (Proxmox VE) is an open-source server virtualization management platform to manage VMs and containers.
Linux KVM can work as a type-1 and type-2 hypervisor.
Type-2 Hypervisor Example: Virtualbox
VirtualBox is an x86 and AMD64/Intel64 virtualization product from Oracle (open-source, free to use), running on Windows, Linux, Mac OS X, and Solaris hosts and supporting various guest OSes.
It provides two virtualization choices: software-based virtualization and hardware-assisted virtualization. It provides the ability to run virtualized applications side-by-side with normal desktop applications.
VM Management
Now, using Virtualbox, VMWare is good. However, the administrator still has to manually install the OS, such as selecting the RAM, hard disk size, keyboard layout, and other settings, which is quite time-consuming. Configuring and sharing one VM is easy; however, managing multiple VM and manually performing all the build and configuration steps can be complicated.
VM Management allows to automate the setup of one or more VMs, resulting in saved time, increased productivity, and lower operational costs.
Vagrant
Vagrant allows VM management and allows
to have consistency in infrastructure provisioning. Vagrant helps to
automate VMs management by providing an end-to-end lifecycle management
utility - the vagrant command-line tool.
Using virtual machines in a development environment allows us to have a reproducible environment and share the environment with other teammates.
Vagrant defines the virtual machines in a Vagrantfile.
Vagrant file
The Vagrantfile
describes how VM should be configured and provisioned.
It is a text file with the Ruby syntax providing information about configuring and provisioning a set of machines.
It includes information about the machine type, image, networking, provider-specific information, and provisioner details.
Now, if we consider what information should be present in the
Vagrantfile
Boxes: should contain what OS needs to be run.
how the access to the OS is provided (ssh/RDP/vnc)
Networking: how the network is configured (host-only/bridge/NAT)
Providers: which hypervisor is used to provide the configuration (Virtualbox/Hyper-V/KVM)
Provisioning: how the machine is provisioned when the machine is booted first.
Synced Folders: OS might require to share data (folders) between the host OS and the VM.
Boxes
Boxes are the package format for the Vagrant environment. The Vagrantfile requires an image used to instantiate VM. If the image is not available locally, vagrant downloads it from a central image repository such as the Vagrant Cloud box repository. Box images can be versioned and customized to specific needs simply by updating the Vagrantfile accordingly.
For instance:
Providers
Providers are the underlying engines or hypervisors used to provision VMs or containers.
Vagrant has VirtualBox as a default provider and supports Hyper-V, Docker, VMWare hypervisors. Custom providers such as KVM, AWS may be installed as well.
Synced Folders
Synced Folder allows syncing a directory on the host system with a VM, which helps the user manage shared files/directories easily.
Provisioning
Provisioners allow us
to automatically install software and make configuration changes after
the machine is booted as a part of the vagrant up process.
Many types of provisioners are available, such as
File,
Shell,
Ansible/Puppet/Chef/Salt
Docker,
For example, Shell as the provisioner to install the vim package.
config.vm.provision "shell", inline: <<-SHELL
yum install vim -y
SHELL
Plugins
Plugins extend the functionality of vagrant.
Networking
Vagrant provides high-level networking options for port forwarding, network connectivity, and network creation.
Multi-Machine
A project’s Vagrantfile may describe multiple VMs, which are typically intended to work together or maybe linked between themselves.
Deployment Models
Infrastructure as a Service
Infrastructure as a Service (IaaS) is a cloud service model that provides on-demand physical and virtual computing resources, storage, network, firewall, and load balancers. To provide virtual computing resources, IaaS uses hypervisors, such as Xen, KVM, VMware ESXi, Hyper-V, or Nitro.
IaaS providers
Platform as a Service
Platform as a Service (PaaS) is a cloud service model representing a class of cloud computing services that allow users to develop, run, and manage applications rather than manage the underlying infrastructure.
Users have a choice between managed and self-managed PaaS solutions. Users can either use
managed PaaS solutions hosted by cloud computing providers.
or deploy an
on-premise PaaS as a self-managed solution, using a platform such as Red Hat OpenShift/OKD.
PaaS can be deployed on top of IaaS or independently on VMs, bare-metal servers, and containers.
PaaS providers
Cloud Foundry (CF)
CF is an open-source PaaS framework. It provides a highly efficient, modern model for cloud-native application delivery on top of Kubernetes.
CF provides application portability, auto-scaling, isolation, centralized platform management, centralized logging, dynamic routing, application health management, role-based application deployment, horizontal and vertical scaling, security, support for different IaaS platforms.
Cloud Foundry Runtimes
CF utilizes two runtimes to manage and run applications and containers separately. Both runtimes are managed by CF BOSH. BOSH is a cloud-agnostic open-source tool for release engineering, deployment, and lifecycle management of complex distributed systems.
Cloud Foundry Application Runtime (CFAR) allows developers to run applications written in any language or framework on the cloud of their choice. It uses buildpacks to provide the framework and runtime support for applications.
Buildpacks are programming language-specific and include information on how to download dependencies and configure specific applications.
When an application is pushed, CF automatically detects an appropriate buildpack for it to compile or prepare the application for launch.
Cloud Foundry Container Runtime (CFCR) offers users to deploy cloud-native, developer-built, pre-packaged applications in containers. The CFCR platform manages containers on a Kubernetes cluster (managed by CF BOSH).
KubeCF
KubeCF is a distribution of CFAR optimized for Kubernetes. It allows developers on CFAR to enjoy the benefits of Kubernetes, just as developers using CFCR do.
KubeCF operates in conjunction with two incubating projects of CF:
Project Quarks is an incubating effort within the CF Foundation to integrate CF and Kubernetes. It packages the CFAR as containers instead of virtual machines, enabling easy deployment to Kubernetes. The resulting containerized CFAR provides an equivalent developer experience to that of BOSH-managed Cloud Foundry installations, requires less infrastructure capacity, and delivers an operational experience familiar to Kubernetes operators.
Project Eirini is a Kubernetes backend for CF. It deploys CF apps to a Kube backend, using OCI images and Kube deployments.
OpenShift/OKD
OpenShift is an open-source PaaS solution provided by Red Hat. It is built on top of the container technology orchestrated by Kubernetes.
OKD is the Community Distribution of Kubernetes that powers Red Hat’s OpenShift.
OKD is a distribution of Kubernetes optimized for continuous application development and multi-tenant deployment. OKD adds developer and operations-centric tools on top of Kubernetes to enable rapid application development, easy deployment and scaling, and long-term lifecycle maintenance for small and large teams.
Users can deploy OpenShift
in the cloud or
locally on a full-fledged Linux OS or
on a Micro OS specifically designed to run containers and Kubernetes.
OpenShift uses the Source-to-Image (S2I) framework that enables users to build container images from the source code repository allowing for fast and easy application deployments. OpenShift integrates well with Continuous Deployment tools to deploy applications as part of the CI/CD pipeline. Applications are managed with ease through command line (CLI) tools, web user interface (UI), and integrated development environment (IDE) available for OpenShift.
Heroku
Heroku is a fully managed container-based cloud platform with integrated data services and a strong ecosystem. Heroku is used to deploy and run modern applications. The Heroku Platform supports the popular languages and frameworks: Node.js, Ruby, Python, Go, PHP, Clojure, Scala, Java.
To learn deployment on an application on the Heroku platform, follow the Getting Started on Heroku, a step-by-step guide for deploying your first app and mastering the basics of Heroku.
Containers
Previously, when an administrator wanted to deploy ten web applications, they might create ten virtual machines and run applications. Further, they may also choose to deploy ten applications on a single machine. However, when multiple applications are deployed on one host, developers are faced with the challenge of isolating applications from one another to avoiding conflicts between dependencies, libraries, and runtimes.
Also, a developer’s end goal is to create a portable application that works consistently on multiple hardware and platforms, such as the developer’s laptop, VMs, data centers, public and private clouds, from the development environment to production. However, they usually end up in situations that the applications work on their laptop but not on another machine. Using a container technology like Docker, users can bundle the application and its dependencies in a box. Users can ship the box to different platforms, and it will run identically on each one of them.
Docker - What is a Container defines a container as a standard unit of software that packages up code and all its dependencies, so the application runs quickly and reliably from one computing environment to another.
Containers vs VM
A virtual machine runs on top of a hypervisor, which virtualizes a host system’s hardware by emulating CPU, memory, and networking hardware resources so that a guest OS can be installed on top of them. Between an application running inside a guest OS and in the outside world, there are multiple layers:
the guest OS,
the hypervisor, and
the host OS.
In contrast to VMs, containers run directly as processes on the host OS. There is no indirection as we see in VMs, which helps containers to achieve near-native performance. Also, as the containers have a very light footprint, it becomes easier to pack more containers than VMs on the same physical machine.
When running containers, we have to ensure that container OS is same as the host OS as it is operating system level virtualization. For instance, Linux containers can only be run over a Linux host OS; Windows containers can only be run over a Windows host OS; Linux containers can not be executed over Windows host OS or vice-versa.
Docker presents how the application is deployed in containers and VMs.
Images and Containers
A Docker container image is a lightweight, standalone, executable package of software that includes everything needed to run an application: code, runtime, system tools, system libraries, and settings.
A running instance of the above image is referred to as a container. We can run multiple containers from the same image.
An image contains the application, its dependencies, and the user-space libraries. User-space libraries like
glibcenable switching from the user-space to the kernel-space. An image does not contain any kernel-space components.When a container is created from an image, it runs as a process on the host’s kernel. The host kernel’s job is to isolate the container process and provide resources to each container.
Julia Evans has provided a good summary of what’s a container.
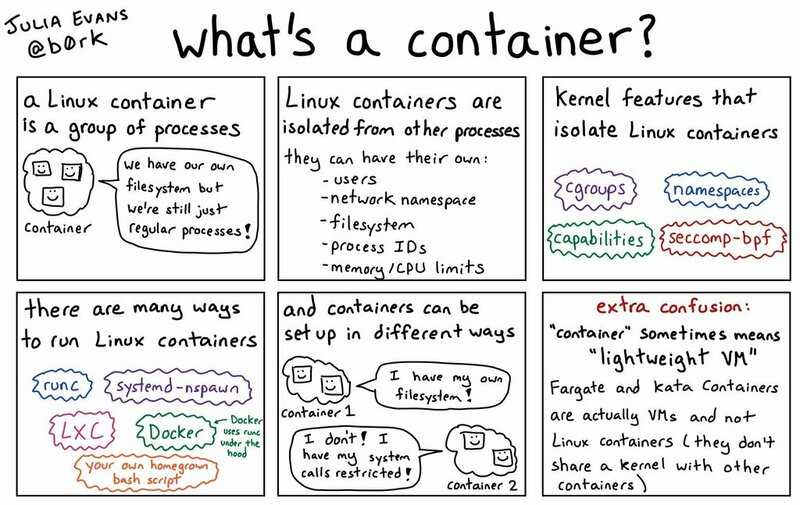
What’s a container
Container Technology: Building Blocks
The Linux kernel provides basic building blocks of container technology.
Namespaces
A namespace wraps a global system resource in an abstraction that makes it appear to the processes within the namespace that they have their own isolated instance of the global resource.
Julia Evans has provided a good summary of what’s a namespace.
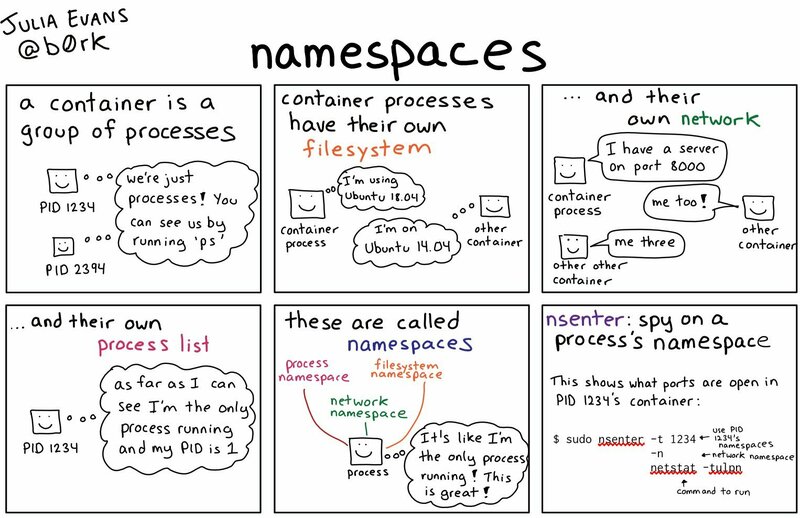
What’s a Namespace

What’s a Namespace
The following global resources are namespaced:
pid
Provides each namespace to have the same PIDs. Each container has its own PID 1.

What’s a PID Namespace
network
Allows each namespace to have its network stack. Each container has its own IP address.
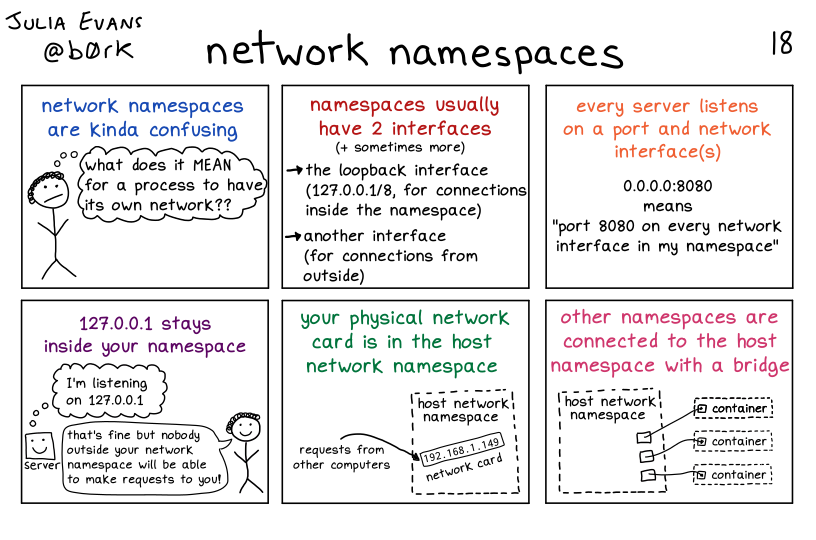
What’s a Network Namespace
user
Allows each namespace to have its user and group ID number spaces. A root user inside a container is not the host’s root user on which the container is running.
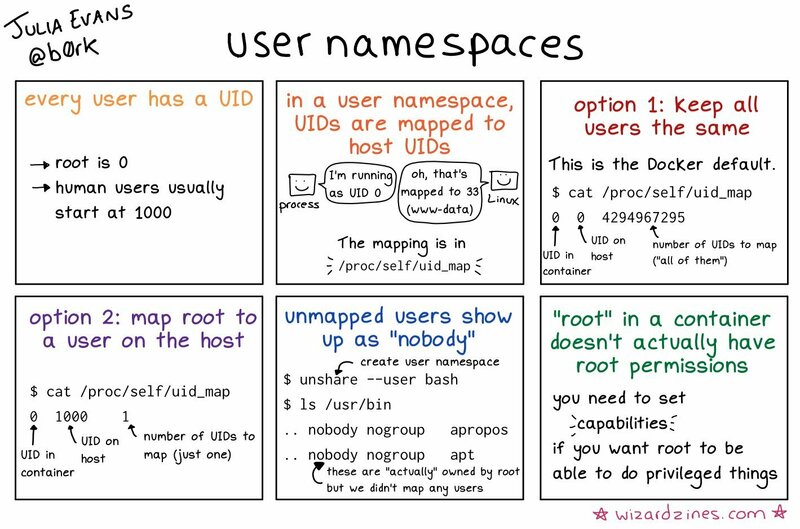
What’s a User Namespace
mnt
Allows each namespace to have its own view of the filesystem hierarchy.
ipc
Allows each namespace to have its own interprocess communication.
uts
Allows each namespace to have its own hostname and domain name.
cgroups
Control groups organize processes hierarchically and distribute system resources along the hierarchy in a controlled and configurable manner. The following cgroups are available for Linux:
blkio
cpu
cpuacct
cpuset
devices
freezer
memory.
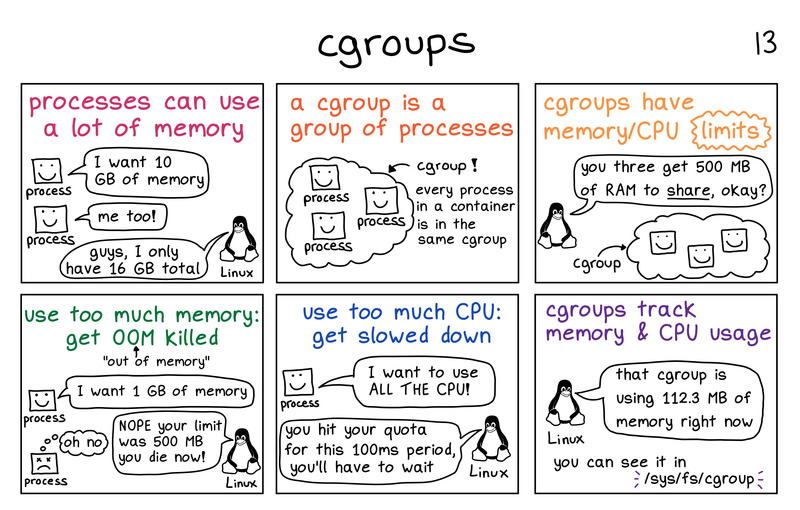
What’s a cgroup
Union filesystem
The Union filesystem allows files and directories of separate filesystems, known as layers, transparently overlaid on top of each other to create a new virtual filesystem.
An image used in Docker is made of multiple layers. While starting a new container, we merge all those layers to create a read-only filesystem.
On top of a read-only filesystem, a container gets a read-write layer, an ephemeral layer, and local to the container.
Container Runtimes
Now, we have learned about container images. These images need to be executed and running for becoming a container. To run them, we need a container runtime. The container runtime ensures container portability, offering a consistent environment for containers to run, regardless of the infrastructure.
runC
Open Container Initiative (OCI) ensures that there is no vendor locking and no inclination towards a particular company or project. The governance body came up with both runtime and image specifications to create standards on the Operating System process and application containers.
runC is the CLI tool for spawning and running containers.
containerd
containerd is an OCI-compliant container runtime emphasizing simplicity, robustness, and portability. It runs as a daemon and manages the entire lifecycle of containers. Docker uses containerd as a container runtime to manage runC containers.
CRI-O
CRI-O is an OCI-compatible runtime, which is an implementation of the Kubernetes Container Runtime Interface (CRI). It is a lightweight alternative to using Docker as the runtime for Kubernetes.
Docker
Docker Containerization Platform runs applications using containers. It comes in two versions:
Docker Enterprise: It is a paid, enterprise-ready container platform created to run and manage containers, currently part of Mirantis.
Docker Engine - Community: It is a free platform used to run and manage containers.
Docker has a client-server architecture, with a Docker Client connecting to a Docker Host server to execute commands.
Project Moby
A container platform like Docker runs on different platforms and architectures: bare metal (both x86 and ARM), Linux, Mac OS-X, and Windows.
From the user perspective, the experience is seamless, regardless of the underlying platform. However, behind the scenes, any container platform contains multiple components such as container runtime, networking, and storage connected to provide a high-quality experience.
However, what if the end-user wants to create their container platform from individual components and build a container platform like Docker? The end-user can create their platform by using Project Moby.
Project Moby is an open-source project that provides a framework for assembling different container systems to build a container platform like Docker. Individual container systems provide features such as image, container, and secret management. Moby is beneficial if the user wants to build a container-based system or experiment with the latest container technologies. It is not recommended for application developers and newbies looking for an easy way to run containers.
LinuxKit is a toolkit for building secure, portable, and lean operating systems for containers uses Moby.
Containers: Micro OSes for Containers
Having understood the working of containers and running applications in containers, it makes sense to run containers on secure, portable, and lean operating systems. Users can create a minimal OS for running containers by eliminating all the packages and services of the host OS, which are not essential for running containers.
Vendors have created specialized minimal OSes to run just containers. Once we remove the packages that are not essential to boot the base OS and run container-related services, we are left with specialized OSes, referred to as Micro OSes for containers. Some examples of Micro OSes are:
Alpine Linux
Fedora CoreOS (formerly known as Red Hat CoreOS)
Ubuntu Core
VMware Photon.
Alpine Linux
Alpine Linux is a
security-oriented, lightweight Linux distribution based on musl libc and
busybox. It uses its own package manager called apk, the OpenRC init
system, script-driven setups. Alpine Linux was designed with security in
mind. All userland binaries are compiled as Position Independent
Executables (PIE) with stack smashing protection. It requires 8 MB
running as a container. It requires 130 MB as a standalone minimal OS
installation.
Upon installation completion, Alpine Linux makes available tools for the system’s initial configuration. Once prepared for a reboot, it can be configured to boot in one of the three available runtime modes:
diskless mode: The default mode, where the entire system runs from RAM.
data mode: Mostly runs from RAM but mounts
/varas a writable data partition.sys mode: The typical hard-disk install that mounts
/boot,swap, and/.
Fedora CoreOS
Fedora CoreOS (FCOS)
is an automatically updating, minimal, monolithic, container-focused
operating system, designed for clusters but also operable standalone,
optimized for Kubernetes. It aims to combine the best of both CoreOS
Container Linux and Fedora Atomic Host (FAH), integrating technology
like Ignition from Container Linux with rpm-ostree and SELinux
hardening from Project Atomic. Its goal is to provide the best container
host to run containerized workloads securely and at scale.
Fedora CoreOS Frequently Asked Questions and Getting Started with Fedora CoreOS is a good way to understand more about Fedora CoreOS, and its relationship with Atomic Host/RedHat CoreOS.
Ubuntu Core
Ubuntu Core is a version of Ubuntu optimized for IoT-native embedded systems. Ubuntu Core carries only packages and binaries for your single-purpose appliance. Ubuntu Core is a container OS built on snaps. With snaps, embedded systems benefit from security, immutability, as well as modularity, and composability. Software is updated over the air through deltas that can automatically roll back in case of failure.
It is essential to read about Ubuntu Core, documentation, tutorials and the whitepapers explaining various security features such as full-disk encryption, application confinement, bare essentials packages, automatic scanning of all snaps for vulnerable libraries and problematic code, secure boot.
Photon OS
Photon OS is a Linux-based, open-source, security-hardened, enterprise-grade appliance operating system purpose-built for Cloud and Edge applications.
Photon OS provides a lightweight container host; It follows the recommendation of Kernel Self-Protection Project (KSPP) by building the packages with hardened security flags and can be easily updated and verified. More information can be read using the Documentation
Containers: Container Orchestration
We have understood containers, the OSs that are optimized to run containers. Till now, we have covered running containers on a single node. However, there might be a case where containerized workload needs to be managed at scale. To run containers in a multi-host environment at scale, there could be multiple issues such as:
How to group multiple hosts together to form a cluster and manage them as a single compute unit?
How to schedule containers to run on specific hosts?
How can containers running on one host communicate with containers running on other hosts?
How to provide the container with dependent storage when it is scheduled on a specific host?
How to access containers over a service name instead of accessing them directly through their IP addresses?
Container orchestration tools and different plugins (for networking and storage) can perform container scheduling and cluster management. Container scheduling allows us to decide which host a container or a group of containers should be deployed. With cluster management orchestrators, we can manage the resources of cluster nodes and add or delete nodes from the cluster. Few container orchestration tools are:
Docker Swarm
Kubernetes
Mesos Marathon
Nomad
Docker Swarm
Current versions of Docker include swarm mode for natively managing a cluster of Docker Engines called a swarm. Use the Docker CLI to create a swarm, deploy application services to a swarm, and manage swarm behavior.
It would be a good idea to read about the Swarm key concepts and then follow the Getting started with swarm mode
Kubernetes
Kubernetes, also known as K8s, is an open-source system for automating deployment, scaling, and management of containerized applications. It groups containers that make up an application into logical units for easy management and discovery. Kubernetes supports several container runtimes such as containerd, CRI-O, and any other implementation of the Kubernetes CRI (Container Runtime Interface).
Kubernetes Concepts has all the documentation we need. It might be a good idea to start the reading from
Cluster Architecture: Read about the Nodes and Control Plane - Node communication.
Containers : Read about images
Workloads: Read about Pods, Pods Lifecycle, Init Containers
Workload Resources: Read about Deployments, ReplicaSet, StatefulSets, DaemonSet, Jobs
Storage: Read about Volumes, Persistent Volumes, Ephemeral Volumes
Apache Mesos/DC-OS/Marathon
Apache Mesos
Apache Mesos abstracts CPU, memory, storage, and other compute resources away from machines (physical or virtual), enabling fault-tolerant and elastic distributed systems to be built and run effectively. The Mesos kernel runs on every machine and provides applications (e.g., Hadoop, Spark, Kafka, Elasticsearch) with API’s for resource management and scheduling across entire datacenter and cloud environments.
Maybe start
DC/OS
DC/OS (the Distributed Cloud Operating System) is an open-source, distributed operating system based on the Apache Mesos distributed systems kernel. DC/OS manages multiple machines in the cloud or on-premises from a single interface; deploys containers, distributed services, and legacy applications into those machines; and provides networking, service discovery, and resource management to keep the services running and communicating with each other.
Marathon
Marathon is a production-grade container orchestration platform for Mesosphere’s Datacenter Operating System (DC/OS) and Apache Mesos.
Hashicorp Nomad
Nomad is a simple and flexible workload orchestrator to deploy and manage containers and non-containerized applications across on-prem and clouds at scale.
Read Explore Nomad
Kubernetes Hosted Solutions
There are many hosted solutions available for Kubernetes, including:
Amazon Elastic Kubernetes Service (Amazon EKS): Offers a managed Kubernetes service on AWS.
Azure Kubernetes Service (AKS): Offers managed Kubernetes clusters on Microsoft Azure.
Google Kubernetes Engine (GKE): Offers managed Kubernetes clusters on Google Cloud Platform.
IBM Cloud Kubernetes Service: Fully managed Kubernetes service at scale, providing continuous availability and high availability, multi-zone, and multi-region clusters.
NetApp Project Astra (fusion between NetApp and Stackpoint.io): Provides Kubernetes infrastructure automation and management for multiple public clouds optimized for stateful application data lifecycle management.
Oracle Container Engine for Kubernetes (OKE): Enterprise-grade Kubernetes service offering highly available clusters optimized to run on Oracle Cloud Infrastructure.
Red Hat OpenShift: Offers managed Kubernetes clusters powered by Red Hat on various cloud infrastructures such as AWS, GCP, Microsoft Azure, and IBM Cloud.
VMware Tanzu Kubernetes Grid (TKG): An enterprise-grade multi-cloud Kubernetes service that runs both on-premise in vSphere and in the cloud.
Cloud Container Orchestration Services
Amazon Elastic Container Service
Amazon Elastic Container Service (Amazon ECS) is a fully managed container orchestration service that helps to easily deploy, manage and scale containerized applications. It deeply integrates with the rest of the AWS platform to provide a secure and easy-to-use solution for running container workloads in the cloud and now on client infrastructure with Amazon ECS Anywhere.
Azure Container Instances
Azure Container Instances provides developing apps fast without managing virtual machines or having to learn new tools — it is just an application, in a container, running in the cloud. They expose containers directly to the internet through IP addresses and fully qualified domain names (FQDN).
Unikernels
Unikernels website defines Unikernels are specialized, single-address-space machine images constructed using library operating systems.
Key benefits of unikernels:
Improved security
Small footprints
Highly optimized
Fast Boot
There are many implementations of unikernels:
Mirage OS: MirageOS is a library operating system that constructs unikernels for secure, high-performance network applications across various cloud computing and mobile platforms. Code can be developed on a standard OS such as Linux or macOS, and then compiled into a fully standalone, specialized unikernel that runs under a Xen or KVM hypervisor.
OSv: OSv is the versatile modular unikernel designed to run unmodified Linux applications securely on micro-VMs in the cloud.
unik: UniK is a tool for compiling application sources into unikernels (lightweight bootable disk images) and MicroVM rather than binaries. UniK runs and manages instances of compiled images across a variety of cloud providers as well as locally. UniK utilizes a simple docker-like command line interface, making building unikernels and MicroVM as easy as building containers.
Microservices
Wikipedia defines Microservices are small, independent processes that communicate with each other to form complex applications which utilize language-agnostic APIs. These services are small building blocks, highly decoupled and focused on doing a small task, facilitating a modular approach to system-building. The microservices architectural style is becoming the standard for building continuously deployed systems
Modern application development involves developing, deploying, and managing a single application via a small set of services. Each service runs its process and communicates with other services via lightweight mechanisms like REST APIs. Each of these services is independently deployed and managed.
Microservices is a good read, and the below diagram is taken from it.
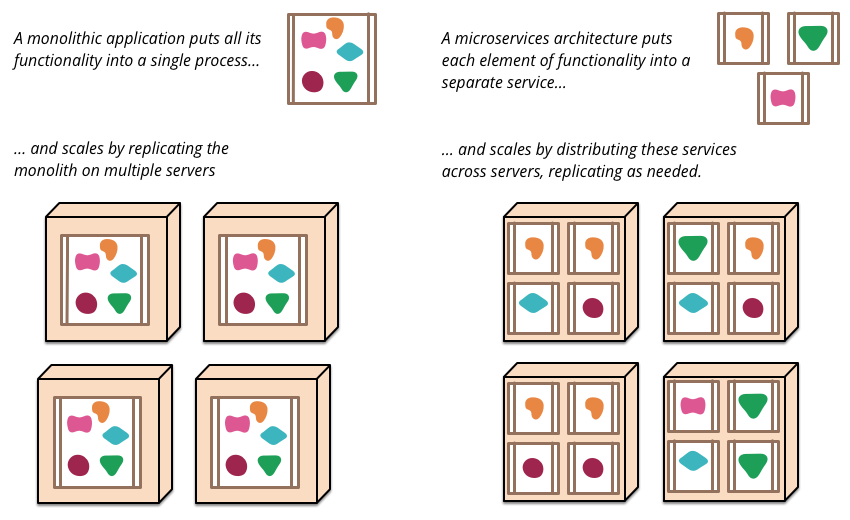
Monoliths and Microservices
Benefits
As each service works and is deployed independently, Developers can develop service components in any languages/technology as long as the API endpoints return the expected output.
Each service can be updated or scaled independently without putting the entire application offline.
Allows developers to reuse the functionality of the service code.
The microservice architecture enables continuous delivery.
Developers can deploy components across multiple servers or even multiple data centers.
Microservices work very well with container orchestration tools (Kubernetes, DC/OS, and Docker Swarm).
Disadvantages
Choosing the right service size: As we need to refactor the monolith application or create microservices from scratch, it is essential to decide on a suitable functionality for a service. If there are too many microservices, the complexity would be large.
Deployment: Deploy of microservice requires a distributed environment such as Kubernetes.
Testing: Requires end-to-end testing of a microservice.
Inter-service communication using either message passing/RPC needs to be implemented effectively.
Managing databases: If multiple databases are used, they need to be in sync.
Monitoring: Monitoring individual services and their health, usage can be challenging and requires tools like Sysdig or Datadog.
Software-Defined Networking
Software-Defined Networking (SDN) decouples the network control layer from the traffic forwarding layer, allowing SDN to program the control layer and create custom rules to meet the new networking requirements.
In networking, there are three distinctive planes:
Data Plane: Responsible for handling data packets and apply actions to them based on rules programmed into lookup tables.
Control Plane: Tasked with calculating and programming the actions for the Data Plane. The Control plane defines the forwarding decisions and implements services such as Quality of Service (QoS) and VLANs.
Management Plane: Configure, monitor, and manage the network devices.
Every network device has to perform three distinct activities:
Ingress and egress packets: Process the packets based on the based on forwarding tables.
Collect, process, and manage the network information to make the forwarding decisions. Monitor and manage the network using the tools available in the Management Plane, such as configuring the network device and monitoring it with tools like SNMP (Simple Network Management Protocol).
In Software-Defined Networking, the Control Plane is decoupled from the Data Plane. The Control Plane has a centralized view of the overall network. It creates the forwarding tables based on which Data Plane manages the network traffic. The control plane can be configured using the API to configure the network, and then rules are communicated to the Data Plane using a well-defined protocol like OpenFlow.
Networking for containers
Containers running on the same host and different hosts should be able to communicate with each other. The host uses the network namespace to isolate the network from one container to another on the system. Network namespaces can be shared between containers as well.
Single Host
Each Linux container can be provided with a virtual network interface with an assigned IP address using the virtual Ethernet (vEth) feature with Linux bridging. Further, the container can be configured with a unique worldwide routable IP address by using Macvlan and IPVlan.
Multi Host
The multi-host networking can be achieved by using the Overlay network driver, which encapsulates the Layer 2 traffic to a higher layer. Such implementations are provided by the Docker Overlay Driver, Flannel, Weave, Calico.
Container Networking Standards
Two different standards have been proposed so far for container networking:
Container Network Model (CNM): Mainly used by Docker. It is implemented using the libnetwork project, which has the following utilizations:
Null: NOOP implementation of the driver. It is used when no networking is required.
Bridge: Provides a Linux-specific bridging implementation based in Linux Bridge.
Overlay: Provides a multi-host communication over VXLAN.
Remote: It does not provide a driver. Instead, it provides a means of supporting drivers over a remote transport, by which developers can write third-party drivers.
Container Networking Interface (CNI): consists of a specification and libraries for writing plugins to configure network interfaces in Linux containers, along with several supported plugins. CNI concerns itself only with network connectivity of containers and removing allocated resources when the container is deleted. It is used by projects like Kubernetes, OpenShift, and Cloud Foundry.
Service Discovery
Service discovery is a mechanism by which processes and services can find each other automatically and talk to each other. With respect to containers, it is used to map a container name with its IP address to access the container directly by its name without worrying about its exact location (IP address), which may change during the life of the container.
Service discovery is achieved in two steps:
Registration: When a container starts, the container scheduler registers the container name to the container IP mapping in a key-value store such as etcd or Consul. And, if the container restarts or stops, the scheduler updates the mapping accordingly.
Lookup: Services and applications use Lookup to retrieve the IP address of a container so that they can connect to it. The DNS used resolves the requests by looking at the entries in the key-value store used for Registration.
Docker Networking
Single-Host Networking
Networking setup on a single Docker host for its containers.
docker network ls
NETWORK ID NAME DRIVER SCOPE
acb6ec59eaed bridge bridge local
d2b0d4f71517 host host local
15d5ceb9443e none null local
bridge, null, and host are different network drivers available on a single Docker host.
Bridge Network
Linux enables the emulation of a software bridge on a Linux host to
forward traffic between two networks based on MAC (hardware address)
addresses. By default, Docker creates a docker0 Linux bridge. Each
container running on a single host receives a unique IP address from
this bridge unless we specify some other network with the --net=
option. Docker uses Linux’s virtual Ethernet (vEth) feature to create
two virtual interfaces, with the interface on one end attached to the
container and the interface on the other end of the pair attached to the
docker0 bridge.
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:2c:c3:36:7b txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
We can create a new container using the following command, then list its IP address:
$ docker container run -it --name=bb1 busybox /bin/sh
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
1399: eth0@if1400: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
As we can see, the new container received its IP address from the
private IP address range 172.17.0.0/16, which is catered by the
bridge network.
Inspecting Bridge Network
We can inspect the bridge network using
docker inspect bridge
[
{
"Name": "bridge",
"Id": "acb6ec59eaedb2597092898acab922b53f45ba0243161917ab678bf8960bfc27",
"Created": "2020-04-01T17:25:26.004197458Z",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "172.17.0.0/16",
"Gateway": "172.17.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {},
"Options": {
"com.docker.network.bridge.default_bridge": "true",
"com.docker.network.bridge.enable_icc": "true",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.host_binding_ipv4": "0.0.0.0",
"com.docker.network.bridge.name": "docker0",
"com.docker.network.driver.mtu": "1500"
},
"Labels": {}
}
]
Currently, there are not any containers using the bridge; hence
"Containers": {}, is empty. Otherwise, it will contain the list of
containers using the bridge.
Creating a network bridge
A custom bridge network can be created using
docker network create --driver bridge my_bridge
It creates a custom Linux bridge on the host system. To create a
container and have it use the newly created network, we have to start
the container with the --net=my_bridge option:
docker container run --net=my_bridge -itd --name=c2 busybox
Null Driver
As the name suggests, NULL means no networking. If we attach a container to a null driver, then it would just get the loopback interface. It would not be accessible from any other network.
docker container run -it --name=c3 --net=none busybox /bin/sh
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
Host Driver
Using the host driver, the host machine’s network namespace is shared
with a container. By doing so, the container would have full access to
the host’s network, which is not a recommended approach due to its
security implications. We can see below that running an ifconfig
command inside the container lists all the interfaces of the host
system:
docker container run -it --name=c4 --net=host busybox /bin/sh
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq qlen 1000
link/ether dc:a6:32:e5:8d:dc brd ff:ff:ff:ff:ff:ff
inet 192.168.1.207/24 brd 192.168.1.255 scope global dynamic eth0
valid_lft 63319sec preferred_lft 63319sec
inet6 2a00:23c7:8a86:7c00:dea6:32ff:fee5:8ddc/64 scope global dynamic noprefixroute flags 100
valid_lft 315359969sec preferred_lft 315359969sec
inet6 fdaa:bbcc:ddee:0:dea6:32ff:fee5:8ddc/64 scope global noprefixroute flags 100
valid_lft forever preferred_lft forever
inet6 fe80::dea6:32ff:fee5:8ddc/64 scope link
valid_lft forever preferred_lft forever
3: wlan0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop qlen 1000
link/ether dc:a6:32:e5:8d:dd brd ff:ff:ff:ff:ff:ff
5: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue
link/ether 02:42:2c:c3:36:7b brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:2cff:fec3:367b/64 scope link
valid_lft forever preferred_lft forever
Sharing Network Namespaces Among Containers
Similar to the host, we can share network namespaces among containers. As a result, two or more containers can share the same network stack and reach each other through localhost.
Now, if we start a new container with the --net=container:CONTAINER
option, we can see that the second container has the same IP address.
docker container run -it --name=c6 --net=container:c5 busybox /bin/sh
Multi-Host Networking
Docker also supports multi-host networking, allowing containers from one Docker host to communicate with containers from another Docker host..
Docker Overlay Driver: libnetwork, a built-in VXLAN-based overlay network driver allows docker to encapsulate the container’s IP packet inside a host’s packet while sending it over the wire. While receiving, Docker on the other host decapsulates the whole packet and forwards the container’s packet to the receiving container.
Macvlan driver: Docker assigns a MAC (physical) address for each container and makes it appear as a physical device on the network. As the containers appear in the same physical network as the Docker host, they can be assigned an IP from the network subnet as the host. As a result, direct container-to-container communication between different hosts is possible. Containers can also directly talk to hosts.
Docker Plugins
Docker allows extending the functionality of Docker Engine by implementing network, volume, and authentication plugins.
Networking Plugins. For instance:
Contiv Networking Plugin: Provides infrastructure and security policies for multi-tenant deployments.
Infoblox IPAM Plugin: Infoblox ipam-plugin is a Docker libnetwork plugin that interfaces with Infoblox to provide IP Address Management services.
Kuryr Network Plugin: It is a part of the OpenStack Kuryr project, which also implements libnetwork’s remote driver API by utilizing Neutron, which is OpenStack’s networking service.
Weave Net Network Plugin: Weave Net provides multi-host container networking for Docker. It also provides service discovery and does not require any external cluster store to save the networking configuration.
Kubernetes Networking
Kubernetes assigns a unique IP address to each pod. Containers in a Pod share the same network namespace and can refer to each other by localhost. Containers in a Pod can expose unique ports and become accessible through the same pod IP address. As each pod gets a unique IP, Kubernetes assumes that Pods should be able to communicate with each other, irrespective of the nodes they get scheduled on.
Kubernetes introduced the Container Network Interface (CNI) specification for container networking together with the following requirements that need to be implemented by Kubernetes networking driver developers:
All pods on a node can communicate with all pods on all nodes without NAT
All nodes can communicate with all pods (and vice versa) without NAT
The IP that a pod sees itself as is the same IP that other pods see.
Implementations of Kubernetes networking:
Cilium: Provides secure network connectivity between application containers. It is L7/HTTP aware and can also enforce network policies on L3-L7.
Flannel: Flannel uses the overlay network, as we have seen with Docker, to meet the Kubernetes networking requirements.
NSX-T: NSX-T from VMware provides network virtualization for a multi-cloud and multi-hypervisor environment. The NSX-T Container Plug-in (NCP) provides integration between NSX-T and container orchestrators such as Kubernetes.
Calico: Calico uses the BGP protocol to meet the Kubernetes networking requirements.
Read About networking
Read Network Policy
Weave Net: Weave Net, a simple network for Kubernetes, may run as a CNI plugin or standalone. It does not require additional configuration to run. The network provides the one IP address per pod, as required and expected by Kubernetes.
Cloud Foundry: Container to Container Networking
By default, Gorouter routes the external and internal traffic to different Cloud Foundry (CF) components.
The container-to-container networking feature of CF enables application instances to communicate with each other directly. However, when the container-to-container networking feature is disabled, all application-to-application traffic must go through the Gorouter.
Container-to-container networking is made possible by several components of the CF architecture:
Policy Server: A management node hosting a database of app traffic policies.
Garden External Networker: Sets up networking for each app through the CNI plugin, exposing apps to the outside by allowing incoming traffic from Gorouter, TCP Router, and SSH Proxy.
Silk CNI Plugin: For IP management through a share VXLAN overlay network that assigns each container a unique IP address. The overlay network is not externally routable, and it prevents the container-to-container traffic from escaping the overlay.
VXLAN Policy Agent: Enforces network policies between apps. When creating routing rules for network policies, we should include the source app, destination app, protocol, and ports without going through the Gorouter, a load balancer, or a firewall.
Software-Defined Storage and Storage Management
Software-Defined Storage
Software-Defined Storage (SDS) represents storage virtualization. The underlying storage hardware is separated from the software that manages and provisions it. The physical hardware from various sources is combined and managed with software as a single storage pool. SDS replaces static and inefficient storage solutions backed directly by physical hardware with dynamic, agile, and automated solutions. SDS provides resiliency features such as replication, erasure coding, and snapshots of the pooled resources. Once the pooled storage is configured in a storage cluster, SDS allows multiple access methods such as File, Block, and Object.
Examples of Software-Defined Storage are: Ceph, FreeNAS, Gluster, LINBIT, MinIO, Nexenta, OpenEBS, VMware vSAN.
Ceph
Ceph is a unified, distributed storage system designed for excellent performance, reliability, and scalability. Ceph supports applications with different storage interface needs. It provides object, block, and file system storage in a single unified storage cluster, making Ceph flexible, highly reliable, and easy to manage.
GlusterFS
Gluster is a free and open-source software scalable network file system. Gluster can utilize common off-the-shelf hardware to create large, distributed storage solutions for media streaming, data analysis, and other data and bandwidth-intensive tasks.
Storage Management for Containers
Containers are ephemeral, meaning that all data stored inside the container’s file system would be lost when the container is deleted. It is best practice to store data outside the container, which keeps the data accessible even after the container is deleted.
In a multi-host or clustered environment, containers can be scheduled to run on any host. We need to make sure the data volume required by the container is available on the host on which the container is scheduled to run.
Docker Storage Backends
Docker uses the copy-on-write mechanism when containers are started from container images. The container image is protected from direct edits by being saved on a read-only filesystem layer. All of the changes performed by the container to the image filesystem are saved on a writable filesystem layer of the container. Docker images and containers are stored on the host system. We can choose the storage backend for Docker storage, depending on our requirements. Docker supports the following storage backends on Linux: AUFS (Another Union File System), BtrFS, Device Mapper, Overlay, VFS (Virtual File System), ZFS.
Managing Data in Docker
Docker supports several options for storing files on a host system:
Volumes: On Linux, volumes are stored under the
/var/lib/docker/volumesdirectory, and Docker directly manages them. Volumes are the recommended method of storing persistent data in Docker.Bind Mounts: Allow Docker to mount any file or directory from the host system into a container.
Tmpfs: Stored in the host’s memory only but not persisted on its filesystem.
Named pipes (npipe): Commonly used for direct communication between a container and the Docker host.
Docker bypasses the Union filesystem by using the copy-on-write mechanism in the cases of volumes and bind mounts. The writes happen directly to the host directory.
Creating a container with volumes
In Docker, a container with a mounted volume can be created using either the docker container run or the docker container create commands:
docker container run -d --name web -v webvol:/webdata myapp:latest
The above command would create a Docker volume inside the Docker working
directory /var/lib/docker/volumes/webvol/_data on the host system,
mounted on the container at the /webdata mount point. Exact mount
path can be found by using the docker container inspect command:
docker container inspect web
Creating a named volume
We can give a specific name to a Docker volume and then use it for different operations. To create a named volume, we can run the following command:
docker volume create --name my-named-volume
and then mount it.
docker volume ls
Mounting a host directory inside the container
In Docker, a container with a bind mount can be created using either the
docker container run or the docker container create commands:
docker container run -d --name web -v /mnt/webvol:/webdata myapp:latest
It mounts the host’s /mnt/webvol directory to /webdata mount
point on the container as it is being started.
Volume plugins for docker
Volume Plugins extend the functionality of the Docker Engine, allowing integrations with third-party vendors storage solutions with the Docker ecosystem. Examples: Azure File Storage, Blockbridge, DigitalOcean Block Storage, Flocker, gce-docker, GlusterFS, Local Persists, NetApp (nDVP), OpenStorage, REX-Ray, VMware vSphere Storage.
Volume plugins are helping while migrating a stateful container, like a database, on a multi-host environment. In such an environment, we have to make sure that the volume attached to a container is also migrated to the host where the container is migrated or started afresh.
Flocker manages Docker containers and data volumes together by allowing volumes to follow containers when they move between different hosts in the cluster.
Volume Management in Kubernetes
Kubernetes uses volumes to attach external storage to containers managed by Pods. A volume is essentially a directory backed by a storage medium. The volume type determines the storage medium and its contents.
A volume in Kubernetes is linked to a Pod and shared among containers of that pod. The volume has the same lifetime as the pod, but it outlives the containers of that pod, meaning that data remains preserved across container restarts. However, once the pod is deleted, the volume and all its data are lost as well.
Volume types
A volume mounted inside a Pod is backed by an underlying volume type. A volume type decides the properties of the volume, such as size and content type. Volume types supported by Kubernetes are:
awsElasticBlockStore: To mount an AWS EBS volume on containers of a Pod.
azureDisk: To mount an Azure Data Disk on containers of a Pod.
azureFile: To mount an Azure File Volume on containers of a Pod.
cephfs: To mount a CephFS volume on containers of a Pod.
configMap: To attach a decoupled object that includes configuration data, scripts, and possibly entire filesystems, to containers of a Pod.
emptyDir: An empty volume is created for the pod as soon as it is scheduled on a worker node. The life of the volume is tightly coupled with the pod. If the pod dies, the content of emptyDir is deleted forever.
gcePersistentDisk: To mount a Google Compute Engine (GCE) persistent disk into a Pod.
glusterfs: To mount a Glusterfs volume on containers of a Pod.
hostPath: To share a directory from the host with the containers of a Pod. If the pod dies, the content of the volume is still available on the host.
nfs: To mount an NFS share on containers of a Pod.
persistentVolumeClaim: To attach a persistent volume to a Pod.
rbd: To mount a Rados Block Device volume on containers of a Pod.
secret: To attach sensitive information such as passwords, keys, certificates, or tokens to containers in a Pod.
vsphereVolume: To mount a vSphere VMDK volume on containers of a Pod.
Persistant Volumes
Persistent volume subsystem provides APIs to manage and consume the storage. To manage the volume, it uses the PersistentVolume (PV) resource type and to consume it; it uses the PersistentVolumeClaim (PVC) resource type.
Persistent volumes can be provisioned statically or dynamically. For dynamic provisioning of PVs, Kubernetes uses the StorageClass resource, which contains pre-defined provisioners and parameters for the PV creation. With PersistentVolumeClaim (PVC), a user sends the requests for dynamic PV creation, which gets wired to the StorageClass resource.
Volume types that support managing storage using PersistentVolume are: GCEPersistentDisk, AWSElasticBlockStore, AzureFile, AzureDisk, NFS, iSCSI, RBD, CephFS, GlusterFS, VsphereVolume, StorageOS.
Persistent Volumes Claim
A PersistentVolumeClaim (PVC) is a request for storage by a user. Users request for PV resources based on size, access modes, and volume type.
Once a suitable PV is found, it is bound to PVC. After a successful bind, the PVC can be used in a Pod to allow the container’s access to the PV.
Once users complete their tasks and the pod is deleted, the PVC may be detached from the PV, releasing it for possible future use. However, keep in mind that the PVC may be detached from the PV once all the Pods using the same PVC have completed their activities and have been deleted. Once released, the PV can be either deleted, retained, or recycled for future usage, all based on the reclaim policy the user has configured on the PV.
Container Storage Interface (CSI)
Previously, container orchestrators like Kubernetes, Mesos, Docker, and Cloud Foundry have had their specific methods of managing external storage volumes making it difficult for storage vendors, to manage different volume plugins for different orchestrators.
Storage vendors and community members from different orchestrators have worked together to standardize the volume interface and created Container Storage Interface (CSI) such that the same volume plugin would work with different containers orchestrators out of the box.
The role of CSI is to maintaining the CSI specification and the protobuf.
The goal of the CSI specification is to define APIs for dynamic provisioning, attaching, mounting, consumption, and snapshot management of storage volumes. In addition, it defines the plugin configuration steps to be taken by the container orchestrator together with deployment configuration options.
Cloud Foundry Volume Service
On Cloud Foundry, applications connect to other services via a service marketplace. Each service has a service broker, which encapsulates the logic for creating, managing, and binding services to applications. With volume services, the volume service broker allows Cloud Foundry applications to attach external storage.
With the volume bind command, the service broker issues a volume
mount instruction that instructs the Diego scheduler to schedule the app
instances on cells with the appropriate volume driver. In the backend,
the volume driver gets attached to the device. Cells then mount the
device into the container and start the app instance.
Following are some examples of CF Volume Services:
nfs-volume-release: This allows for easy mounting of external Network File System (NFS) shares for Cloud Foundry applications.
smb-volume-release: This allows for easy mounting of external Server Message Block (SMB) shares for Cloud Foundry applications.
DevOps and CI/CD
The collaborative work between Developers and Operations is referred to as DevOps. DevOps is more of a mindset, a way of thinking, versus a set of processes implemented in a specific way.
Besides Continuous Integration (CI), DevOps also enables Continuous Deployment (CD), which can be seen as the next step of CI. In CD, we deploy the entire application/software automatically, provided that all the tests’ results and conditions have met the expectations.
Why CI
When code is developed in an organisation, multiple developers can be contributing to the code and multiple challenges can occur. The following factors need to be taken into consideration while developing and testing the code:
Can overlapping sets of changes be applied simultaneously, or do they conflict (a good revision control system such as git can handle most of this work, but it still often requires human intervention).
When all changes are applied, does the project even compile? For example, one patch set might remove a header file that another one needs. This does not get picked up by the revision control system.
Does it work on all possible targets? That might mean different hardware (say x86 vs. ARM) or different operating systems (say Linux vs. Solaris or Windows) or different library, language, or utility versions.
What does working mean? Are there non-trivial test suites that can exercise a representative workload enough to give confidence things are fine?
Continuous Integration techniques ensure that testing is so frequent that any problems cannot persist for long and that distributed developers stay on the same page. Projects absorb changes rapidly and in real time (usually multiple times per day) and run automated tests to make sure things are in harmony.
Definitions
Continous Integration: Changes are to be merged into the main branch as often as possible. Automated builds are run on as many variations of software and hardware as possible; conflicts are resolved as soon as they arise.
Continous Delivery: The release process is automated and projects are ready to be delivered to consumers of the build. Thorough testing is done on all relevant platforms.
Continous Deployment: The product is released to customers, once again in an automated fashion.
The time gap between these steps is meant to be as close to zero as possible. In a perfect world, developer changes can reach end user customers the same day or even in minutes. These terms can be defined somewhat differently; for example, Continuous Integration can be considered to include both delivery and deployment.
Costs:
Changes have to be merged very often, probably at least once a day, putting a possible strain on developers.
The repository must be monitored by a continuous integration server, which runs scripted automation tests every time contributions are made. Staff has to be allocated to do this.
Scripts and other tools have to be run to perform automated tests, report their results, and take appropriate actions. It can be a lot of work to prepare this infrastructure.
Benefits:
Developers do not go down the wrong path and compound fixable mistakes or get in each other’s way. In the end, this saves time.
The build steps are fully automated, all the work has been done upfront.
Regressions (bugs which break the working product) may be minimized. Releases should have fewer bugs.
CI/CD Tools
Top Continuous Integration Tools: 51 Tools to Streamline Your Development Process, Boost Quality, and Enhance Accuracy provides a good summary of CI tools. Some of the main tools are Jenkins, Travis CI, TeamCity, GoCD, GitLab CI, Bamboo, Codeship, CircleCI.
Some of the software used in the CI/CD domain are Jenkins, Travis CI, Shippable, and Concourse
Jenkins
Jenkins is a open source automation system, part of the CD Foundation. It can provide Continuous Integration (CI) and Continuous Deployment (CD), and it is written in Java. Jenkins can build Freestyle, Apache Ant, and Apache Maven-based projects. We can also extend the functionality of Jenkins, using plugins such as Source Code Management, Slave Launchers, Build tools, and External tools/site integration.
Jenkins also has the functionality to build a pipeline, which allows us to define an entire application lifecycle. A pipeline is most useful for performing Continuous Deployment (CD).
Start reading
Pipeline is a suite of plugins which supports implementing and integrating continuous delivery pipelines into Jenkins.
Travis CI
Travis CI is a hosted, distributed CI solution for projects hosted on GitHub, Bitbucket, and more.
To run the test with CI, first we have to link our GitHub account with
Travis and select the project (repository) for which we want to run the
test. In the project’s repository, we have to create a .travis.yml
file, which defines how our build should be executed step-by-step.
A typical build with Travis consists of two steps:
install: to install any dependency or pre-requisite
script: to run the build script.
There are other optional steps, including the deployment steps. The
following are all the build options one can put in a .travis.yml
file: before_install, install, before_script, script, before_cache,
after_success or after_failure, before_deploy, deploy, after_deploy,
after_script.
Travis CI supports various databases, such as MYSQL, RIAK, and memcached. We can also use Docker during the build process. Travis CI supports most languages.
After running the test, we can deploy the application in many supported cloud providers, such as Heroku, AWS Codedeploy, Cloud Foundry, and OpenShift.
Shippable
Shippable is a DevOps Assembly Lines Platform that helps developers and DevOps teams achieve CI/CD and make software releases frequent, predictable, and error-free. It does this by connecting all your DevOps tools and activities into a event-driven, stateful workflow.
Consource
Concourse is an open source CI/CD system written in the Go language.
CI/CD Kubernetes Tools
Tools that help us with CI/CD, which integrate well with Kubernetes for Cloud Native applications:
Helm : Package manager for Kubernetes. Helm packages Kubernetes applications into Charts, with all the artifacts, objects, and dependencies an entire application needs in order to successfully be deployed in a Kubernetes cluster. Using Helm Charts, which are stored in repositories, we can share, install, upgrade, or rollback an application that was built to run on Kubernetes.
Draft: Developer tool for cloud-native applications running on Kubernetes, and it allows for an application to be containerized and deployed on Kubernetes.
Skaffold: Tool that helps us build, push, and deploy code to the Kubernetes cluster. It supports Helm, and it also provides building blocks and describes customizations for a CI/CD pipeline.
Argo: Container-native workflow engine for Kubernetes. Its use cases include running Machine Learning, Data Processing, and CI/CD tasks on Kubernetes.
Jenkins X: Tool for CI/CD that can be used on Kubernetes. Jenkins X leverages Docker, Draft, and Helm to deploy a Jenkins CI/CD pipeline directly on Kubernetes, by simplifying and automating full CI/CD pipelines. In addition, Jenkins X automates the preview of pull requests for fast feedback before changes are merged, and then it automates the environment management and the promotion of new application versions between different environments.
Spinnaker: Open source multi-cloud continuous delivery platform from Netflix for releasing software changes with high velocity. It supports all the major cloud providers like Amazon Web Services, Microsoft Azure, Google Cloud Platform, and OpenStack. It supports Kubernetes natively.
Other Information:
The Linux kernel development community employs a very robust continuous integration project called kernelci.
Tools for Cloud Infrastructure
Configuration Management
As an administrator, we want to manage and automate numerous systems (both bare-metal and virtual) in different environments like Development, QA, and Production. Infrastructure as Code allows having a consistent and desired state of systems and software installed on them. Configuration Management tools allow us to define the desired state of the systems in an automated way.
Ansible
Ansible is an easy-to-use, open-source Configuration Management (CM) tool. It is an agentless tool that works through SSH. In addition, Ansible can automate infrastructure provisioning (on-premise or cloud), application deployment, and orchestration. Playbooks are Ansible’s configuration, deployment, and orchestration language.
The Ansible management node connects to the nodes listed in the inventory file. It runs the tasks included in the playbook. Administrators can install a management node on any Unix-based system like Linux or Mac OS X. It can manage any node which supports SSH and Python.
Ansible Galaxy is a free site for finding, downloading, and sharing community-developed Ansible roles.
Puppet
Puppet is an open-source configuration management tool. It mostly uses the agent/master (client/server) model to configure the systems. The agent is referred to as the Puppet Agent, and the master is referred to as the Puppet Master. The Puppet Agent can also work locally and is then referred to as Puppet Apply.
Puppet also provides Puppet Enterprise and provides services and training for this product.
Puppet Agent
The Puppet Agent needs to be installed on each system we want to manage/configure with Puppet. Each agent is responsible for:
Connecting securely to the Puppet Master to get the series of instructions in a file referred to as the Catalog File.
Performing operations from the Catalog File to get to the desired state.
Sending back the status to the Puppet Master.
Puppet Agent can be installed on the following platforms: Linux, Windows, Mac OSX.
Puppet Master
Puppet Master can be installed only on Unix-based systems. It is responsible for:
Compiling the Catalog File for hosts based on system, configuration, manifest file, etc.
Sending the Catalog File to agents when they query the master.
Storing information about the entire environment, such as host information, metadata such as authentication keys.
Gathering reports from each agent and then preparing the overall report.
Catalog File
Puppet prepares a Catalog File based on the manifest file. A manifest file is created using the Puppet Code.
Puppet defines resources on a system as Type, which can be a file, user, package, service, etc. They are well-documented in their documentation.
After processing the manifest file, the Puppet Master prepares the Catalog File based on the target platform.
Puppet Tools
Puppet also has nice tooling around it, like:
Centralized reporting through PuppetDB helps us generate reports and search a system, etc.
Live system management.
Puppet Forge has ready-to-use modules for manifest files from the community.
Chef
Chef uses the client/server model to perform configuration management. The Chef client is installed on each host which we want to manage. The server is referred to as Chef Server. Additionally, there is another component called Chef Workstation, which is used to:
Salt Stack
Salt is an open-source configuration management system built on top of a remote execution framework. It can be used in a client/server model or agentless model as well. In a client/server model, the server sends commands and configurations to all the clients in a parallel manner, which the clients run, returning the status. In the agentless mode, the server connects with remote systems via SSH.
Each client is referred to as a Salt minion, receiving configuration commands from the Master, and reporting back results:
A server is referred to as a Salt master. In a default setup, the Salt master and minions communicate over a high-speed data bus, ZeroMQ, which requires an agent to be installed on each minion.
Salt also supports an agentless setup using SSH for secure and encrypted communication between the master and the managed systems.
Build and Release
Infrastructure as a Code helps us create a near production-like environment for development, staging, etc. Now, suppose we want to create the environment on multiple cloud providers. In that case, we can use Infrastructure management tools such as Terraform, CloudFormation, and BOSH.
Terraform
Terraform is a tool that allows us to define the infrastructure as code. This helps us deploy the same infrastructure on Virtual Machines, bare metal, or cloud. It helps us treat the infrastructure as software. The configuration files can be written in HCL (HashiCorp Configuration Language).
Terraform Providers
Physical machines, VMs, network switches, or containers are treated as resources, which providers expose. A provider is responsible for understanding API interactions and exposing resources, making Terraform agnostic to the underlying platforms.
Terraform has providers in different stacks:
IaaS: AWS, DigitalOcean, GCP, OpenStack, Azure, Alibaba Cloud, KVM.
PaaS: Heroku, Cloud Foundry, etc.
SaaS: Atlas, DNSimple, etc.
CloudFormation
CloudFormation is a tool that allows us to define our infrastructure as code on Amazon AWS. The configuration files can be written in YAML or JSON format. At the same time, CloudFormation can also be used from a web console or the command line.
BOSH
BOSH is an open-source tool for release engineering, deployment, lifecycle management, and monitoring of distributed systems.
BOSH supports multiple Infrastructure as a Service (IaaS) providers. BOSH creates VMs on top of IaaS, configures them to suit the requirements, and then deploys the applications on them. Supported IaaS providers for BOSH are Amazon Web Services EC2, OpenStack, VMware vSphere, vCloud Director.
With the Cloud Provider Interface (CPI), BOSH supports additional IaaS providers such as Google Compute Engine and Apache CloudStack.
Key-Value Pair Store
Key-Value Pair Storage provides the functionality to store or retrieve the value of a key. Most of the Key-Value stores provide REST APIs to support operations like GET, PUT, and DELETE, which help with operations over HTTP.
etcd
etcd is a strongly consistent, distributed key-value store that provides a reliable way to store data that needs to be accessed by a distributed system or cluster of machines. It gracefully handles leader elections during network partitions and can tolerate machine failure, even in the leader node. It allows users or services to watch the value of a key and then perform certain operations due to any change in that particular value.
etcd use-cases
Store connections, configuration, cluster bootstrapping keys, and other settings.
Service Discovery in conjunction with tools like skyDNS.
Metadata and configuration data for service discovery.
Container management.
Consul
Consul is a distributed, highly-available system used for service discovery and configuration. Other than providing a distributed key-value store, it also provides features like:
Service discovery in conjunction with DNS or HTTP
Health checks for services and nodes
Multi-datacenter support.
Consul use-cases
Store connections, configuration, and other settings.
Service discovery and health checks in conjunction with DNS or HTTP.
Network infrastructure automation with dynamic load balancing while reducing downtime and outages.
Multi-platform secure service-to-service communication.
ZooKeeper
ZooKeeper is a centralized service for maintaining configuration information, providing distributed synchronization together with group services for distributed applications.
ZooKeeper aims to provide a simple interface to a centralized coordination service that is also distributed and highly reliable. It implements Consensus, group management, and presence protocols on behalf of applications
Zookeeper use-cases
Implement node coordination in a clustered environment.
To manage cloud node memberships while coordinating distributed jobs.
As a backing store for distributed and scalable data structures.
Election of a High Availability master.
As light-weight failover and load balancing manager
Container Image Building
We often need to create an image in an automated fashion from which the service can be started. We can create Docker container images and VM images for different cloud platforms using Packer.
Docker
Docker read instructions from a Dockerfile and generates the requested image. Internally, it creates a container after each instruction and then commits it to persistent storage. FROM, RUN, EXPOSE, and CMD are reserved instructions and are followed by arguments. Sample Dockerfile:
FROM fedora
RUN dnf -y update && dnf clean all
RUN dnf -y install nginx && dnf clean all
RUN echo "daemon off;" >> /etc/nginx/nginx.conf
RUN echo "nginx on Fedora" > /usr/share/nginx/html/index.html
EXPOSE 80
CMD [ "/usr/sbin/nginx" ]
Dockerfiles start from a parent image or a base image, specified with the FROM instruction.
A parent image is an image used as a reference, modified by subsequent Dockerfile instructions.
Users can build parent images directly out of working machines or with tools such as Debootstrap or supermin. The Docker GitHub source code repository also has helper scripts to create base images.
A base image has FROM scratch in the Dockerfile.
Multi-stage Dockerfile
A multi-stage build helps optimize the Dockerfiles and minimize the size of a container image. Through a multi-stage build, we create a new Docker image in every stage. Every stage can copy files from images created either in earlier stages or from already available images.
For example,
In the first stage, we can copy the source code, compile it to create a binary, and then
In the second stage, we can copy just the binary to a resulting image.
Before multi-stage builds, we would need to create multiple Dockerfiles to achieve similar results.
Let’s take a look at the following Dockerfile:
stage - 1
FROM ubuntu AS buildstep
RUN apt update && apt install -y build-essential gcc
COPY hello.c /app/hello.c
WORKDIR /app
RUN gcc -o hello hello.c && chmod +x hello
stage - 2
FROM ubuntu
RUN mkdir -p /usr/src/app/
WORKDIR /usr/src/app
COPY --from=buildstep /app/hello ./hello
COPY ./start.sh ./start.sh
ENV INITSYSTEM=on
CMD ["bash", "/usr/src/app/start.sh"]
The COPY --from=buildstep line copies only the built artifact from
the previous stage into this new stage. The C SDK and any intermediate
artifacts are not copied in the final image.
Packer
Packer is an open-source tool for creating virtual images from a configuration file for different platforms. Configuration files are written using HCL (HashiCorp Configuration Language).
In general, there are three steps to create virtual images:
Building the base image: Defined under the builders section of the configuration file. Packer supports the following platforms: Amazon EC2 (AMI), DigitalOcean, Docker, Google Compute Engine, Microsoft Azure, OpenStack, Parallels (PVM), QEMU, VirtualBox (OVF), and VMware (VMX). Administrators can add other platforms via plugins. Packer offers an advanced feature where it supports multiple images to be created from the same template file. It is called parallel builds, and it ensures “near-identical” images are built for different environments.
Provision of the base image for configuration: Once we build a base image, we can then provision it to configure it further, make changes like install software, etc. Packer supports different provisioners such as Shell, Ansible, Puppet, and Chef.
Perform optional post-build operations: Post-processors allow us to copy/move the resulted image to a central repository or create a Vagrant box.
Debugging, Logging and Monitoring for Containerized Applications
Deploying applications can be problematic and often requires analysis of the problem. Debugging, logging and monitoring tools can help to find the root cause of the problems. Tools such as strace, SAR (System Activity Reporter), tcpdump, GDB (GNU Project Debugger), syslog, Nagios, Zabbix.
We can use the same tools on bare metal and VMs, but containers bring additional challenges:
Containers are ephemeral, so when they are deleted, all their metadata, including logs, gets deleted as well, unless we store it in some other, possibly persistent storage location.
Containers do not have kernel space components.
We want to keep a container’s footprint as small as possible, but installing debugging and monitoring tools make that nearly impossible.
Collecting per container statistics, debugging information individually, and then analyzing data from multiple containers is a tedious process.
Tools that can be used for containerized applications:
Debugging: Docker CLI, Sysdig
Logging: Docker CLI, Docker Logging Driver
Monitoring: Docker CLI, Sysdig, cAdvisor, Prometheus, Datadog, New Relic.
Docker - Debugging
Docker has some built-in command-line options that help with debugging, logging, and monitoring:
Debugging:
docker inspect
docker logs
Logging:
docker logs
Docker Logging Drivers: Logging can be performed either a Docker daemon wide or per container logging policy. Depending on the policy, Docker forwards the logs to the corresponding drivers. Docker supports the following drivers: jsonfile, syslog, journald, gelf (Graylog Extended Log Format), fluentd, awslogs, splunk. Once the logs are saved in a central location.
Monitoring:
docker stats
docker top
Sysdig
Sysdig provides an on-cloud and on-premise platform for container security, monitoring, and forensics.
It provides four open-source products:
Falco: Falco, the cloud-native runtime security project, is the de facto Kubernetes threat detection engine. Falco detects unexpected application behavior and alerts on threats at runtime. Sysdig Secure is the commercial version. Read
Sysdig Inspect: Sysdig Inspect is a powerful opensource interface for container troubleshooting and security investigation.
Cloud Custodian: Opensource Cloud Security, Governance, and Management: Organizations can use Custodian to manage their cloud environments, ensuring compliance to security policies, tag policies, garbage collection of unused resources, and cost management from a single tool.
Prometheus: Prometheus is a systems and service monitoring system. It collects metrics from configured targets at given intervals, evaluates rule expressions, displays the results, and can trigger alerts when specified conditions are observed.
cAdvisor
cAdvisor (Container Advisor) provides container users an understanding of the resource usage and performance characteristics of their running containers. It is a running daemon that collects, aggregates, processes, and exports information about running containers.
Elasticsearch
Elasticsearch is the distributed search and analytics engine at the core of the Elastic Stack. It is responsible for data indexing, search, and analysis. Kibana is an interface that enables interactive data visualization while providing insights into the data.
Elasticsearch provides real-time search and analytics for structured or unstructured text, numerical data, or geospatial data. It is optimized to store efficiently and index data to speed up the search process.
Fluentd
Fluentd is an open-source data collector, which lets you unify the data collection and consumption for better use and understanding of data. It provides multiple plugins.
Others - Commercial
Datadog is the essential monitoring and security platform for cloud applications. We bring together end-to-end traces, metrics, and logs to make your applications, infrastructure, and third-party services entirely observable.
Splunk includes a family of products aiming to deliver highly scalable and fast real-time insight into enterprise data. It allows for data aggregation and analysis with unique investigative methods.
Service Mesh
Service mesh is a network communication infrastructure layer for a microservices-based application. When multiple microservices communicate with each other, a service mesh allows us to decouple resilient communication patterns such as circuit breakers and timeouts from the application code.
Features and Implementation of Service Mesh
Service mesh is generally implemented using a sidecar proxy.
A sidecar is a container that runs alongside the primary application and complements it with additional features like logging, monitoring, and traffic routing.
In the service mesh architecture, the sidecar pattern implements inter-service communication, monitoring, or other features that can be decoupled and abstracted away from individual services.
The following are some of the features of service mesh:
Communication: It provides flexible, reliable, and fast communication between various service instances.
Circuit Breakers: It restricts traffic to unhealthy service instances.
Routing: It passes a REST request for
/foofrom the local service instance, to which the service is connected.Retries and Timeouts: It can automatically retry requests on certain failures and can timeout requests after a specified period.
Service Discovery: It discovers healthy, available instances of services.
Observability: It monitors latency, traces traffic flow, and generates access logs.
Authentication and Authorization: It can authenticate and authorize incoming requests.
Transport Layer Security (TLS) Encryption: It can secure service-to-service communication using TLS.
Data Plane and Control Plane
A service mesh also features Data and Control Planes.
Service Mesh Data Plane: It provides the features mentioned above. It touches every packet/request in the system.
Service Mesh Control Plane: It provides policy and configuration for the Data Plane. For example, we can specify settings for load balancing and circuit breakers by using the control plane.
There are many service mesh projects, which can be divided into two categories:
Data Plane
Linkerd
NGINX
HAProxy
Envoy
Traefik/Maesh.
Control Plane
Istio
Nelson
SmartStack
Consul
Consul is an open-source project aiming to provide a secure multi-cloud service networking through automated network configuration and service discovery.
Envoy
Envoy is an open-source edge and service proxy designed for cloud-native applications. It provides an L7 proxy and communication bus for large, modern, service-oriented architectures. Envoy has an out-of-process architecture, which means it is not dependent on the application code. It runs alongside the application and communicates with the application on localhost (as a sidecar). With the Envoy sidecar implementation, applications need not be aware of the network topology. Envoy can work with any language and can be managed independently. It provides good monitoring using statistics, logging, and distributed tracing. It can provide SSL communication.
Envoy can be configured as a service and edge proxy.
The service type of configuration is used as a communication bus for all traffic between microservices.
With the edge type of configuration, it provides a single point of ingress to the external world.
Istio
Istio Architecture
Istio is divided into the following two planes:
Data Plane: It is composed of Envoy proxies deployed as sidecars to provide a medium for communication and to control all network communication between microservices.
Control Plane: It manages and configures proxies to route traffic, enforces policies at runtime, and collects telemetry. The control plane includes the Citadel, Gallery, and Pilot.
Istio Components
The main components of Istio are:
Envoy Proxy: Istio uses an extended version of the Envoy proxy, using which it implements features like dynamic service discovery, load balancing, TLS termination, circuit breakers, health checks, etc. Envoy is deployed as sidecars.
Istiod: Istiod provides service discovery, configuration, and certificate management
Key features and benefits
Traffic control to enforce fine-grained traffic control with rich routing rules and automatic load balancing for HTTP, gRPC, WebSocket, and TCP traffic.
Network resiliency to setup retries, failovers, circuit breakers, and fault injection.
Security and authentication enforce security policies and enforce access control and rate-limiting defined through the configuration API.
Pluggable extensions model based on WebAssembly allows for custom policy enforcement and telemetry generation for mesh traffic.
Kuma
Kuma is an open-source control plane for service mesh, delivering security, observability, routing. It can be easily set up on VMs, bare-metal, and Kubernetes.
Kuma is based on the Envoy proxy - a sidecar proxy designed for cloud-native applications that supports monitoring, security, and reliability for microservice applications at scale. With Envoy used as a data plane, Kuma can handle any L4/L7 traffic to observe and route traffic between services.
Kuma Architecture
Kuma includes the following two planes:
Control-Plane: Kuma is a control plane that creates and configures policies that manage services within the Service Mesh.
Data-Plane: Implemented on top of Envoy, runs as an instance together with every service to process incoming and outgoing requests.
Kuma Modes
Kuma is a universal control plane that can run on modern environments like Kubernetes and more traditional VM instances. Such flexibility is achieved through two separate running modes:
Universal Mode: Installed on a Linux compatible system such as macOS, VMs, or bare metal, including containers built on Linux-based MicroOSes. In this mode, Kuma needs to store its state in a PostgreSQL database.
Kubernetes Mode: When deployed on Kubernetes, Kuma stores its state and configuration directly on the Kubernetes API Server, injecting a proxy sidecar into desired Kubernetes Pods.
Linkerd
Linkerd is an open-source network proxy. It is ultra-light, ultra-simple, ultra-powerful. Linkerd adds security, observability, and reliability to Kubernetes without the complexity. Linkerd can be installed per host or instance as a replacement for the sidecar deployment.
Mesh
Traefik Mesh is a straightforward, easy to configure, and non-invasive service mesh that allows visibility and management of the traffic flows inside any Kubernetes cluster. It is a simple and easy to configure service mesh that provides traffic visibility and management inside a Kubernetes cluster.
Mesh Architecture
Mesh improves cluster security through monitoring, logging, visibility, and access controls. Communication monitoring and tracing also help with traffic optimization and increased application performance. Mesh can reveal underutilized resources or overloaded services, which helps with proper resources allocation.
Mesh being non-invasive by design, does not require any sidecar containers to be injected into Kubernetes pods. Instead, it routes through proxy endpoints, called mesh controllers, that run on each node as dedicated pods.
Tanzu Service Mesh - Commercial
Tanzu Service Mesh is an enterprise-class service mesh developed by VMware, built on top of VMware NSX. It aims to simplify the connectivity, security, and monitoring of applications on any runtime and on any cloud. In addition, as a modern distributed solution, it brings together application owners, DevOps, SRE, and SecOps
Tanzu Service Mesh consistently connects and secures applications running on all Kubernetes multi-clusters and multi-cloud environments. It can be installed on VMware Tanzu Kubernetes Grid clusters or any Kubernetes clusters, including managed Kubernetes services.
Internet of Things
The Internet of Things (IoT) is the network of physical devices, vehicles, home appliances, and other items embedded with electronics, software, sensors, actuators, and connectivity which enables these things to connect and exchange data, creating opportunities for more direct integration of the physical world into computer-based systems, resulting in efficiency improvements, economic benefits, and reduced human exertions.
Below cloud services providers that also have specialized IoT offerings
Amazon Web Services (AWS): AWS IoT offers various products and services like Amazon FreeRTOS, AWS IoT Core, AWS IoT Device Management, AWS IoT Analytics, and many others.
Google Cloud Platform (GCP): Google Cloud IoT is the IoT offering from Google Cloud Platform, including Cloud IoT Core and Edge TPU services.
Microsoft Azure: Azure IoT offers Azure IoT Hub, Azure IoT Central, and Azure IoT Edge, which provides artificial intelligence (AI), Azure services, and custom logic directly on cross-platform IoT devices.
Serverless Computing
Serverless computing or just serverless is a method of running applications without concerns about the provisioning of computer servers or any of the compute resources. In serverless computing, we generally write applications/functions that focus and master one particular task. We then upload that application on the cloud provider, which gets invoked via different events, such as HTTP requests, webhooks, etc.
The most common use case of serverless computing is to run any stateless applications like data processing or real-time stream processing. However, it can also augment a stateful application. Internet of Things and ChatBots are common use cases of serverless computing.
Key features and benefits of serverless computing include:
No Server Management: When we use serverless offerings by cloud providers, no server management and capacity planning is required by us. It is all handled by the cloud services provider.
Cost-Effective: We only need to pay for a CPU when our applications/functions are executed. There is no charge when code is not running. Also, there is no need to rent or purchase fixed quantities of servers.
Flexible Scaling: We don’t need to set up or tune autoscaling. Applications are automatically scaled up/down based on demand.
Automated High Availability and Fault Tolerance: High availability and fault tolerance are automatically included by the underlying cloud infrastructure providers. Developers are not required to program for such features specifically.
There are some drawbacks of serverless computing that include:
Vendor Lock-In: Serverless features and implementations vary from vendor to vendor. So, the same application/function may not behave the same way if you change the provider, and changing your provider can incur additional expenses.
Multitenancy and Security: You cannot be sure what other applications/functions run alongside yours, which raises multitenancy and security concerns.
Performance: If the application is not in use, the service provider can take it down, which will affect performance.
Resource Limits: Cloud providers set resource limits for our serverless applications/functions. Therefore, it is safer not to run high-performance or resource-intensive workloads using serverless solutions.
Monitoring and Debugging: It is more challenging to monitor serverless applications than applications running on traditional servers.
AWS Lambda
AWS Lambda is the serverless service offered through Amazon Web Services Compute collection of products. AWS Lambda can be triggered in different ways, such as an HTTP request, a new document upload to S3 bucket, a scheduled job, and AWS Kinesis data stream, a notification from AWS Simple Notification Service, or a REST API call through the Amazon API Gateway.
Google Cloud Functions
Google Cloud Functions is essentially a Function-as-a-Service (FaaS) offering and it is complemented by two additional services, App Engine and Cloud Run:
App Engine allows users to build highly scalable applications on a fully managed serverless platform. It supports Node.js, Java, Ruby, C#, Go, Python, PHP, or other programming languages through custom runtime support. Scalability and flexibility are achieved by encapsulating the applications in Docker containers.
Cloud Run is a managed compute platform for fast and secure deployment and scaling of containerized applications. It supports Node.js, Java, Ruby, Go, and Python, and it improves the developer experience by integrating with services such as Cloud Code, Cloud Build, Cloud Monitoring, and Cloud Logging. Cloud Run also enables application portability by implementing the Knative open standard and supporting the Docker runtime.
Google Cloud Functions can be written in Node.js, Python, Go, or Java and can be executed on Debian or Ubuntu systems on the Google Cloud Platform, simplifying and easing portability and local testing.
Azure Functions
Azure Functions is part of Microsoft Azure’s serverless compute offering, together with Serverless Kubernetes and Serverless application environments. Azure Functions offers an event-driven environment. It is available as a managed service in Azure and Azure Stack, but it also works on Kubernetes, Azure IoT Edge, on-premises, and other clouds.
Serverless Kubernetes allows users to create serverless, Kubernetes-based applications orchestrated with Azure Kubernetes Service (AKS) and AKS virtual nodes, based on the open-source Virtual Kubelet project.
Serverless application environments allow the running and scaling of web, mobile, and API applications on any platform of your choice through Azure App Service.
Serverless Computing
Projects That Use Containers to Execute Serverless Applications
Azure Container Instances : Azure Container Instances (ACI) is the service offered by Microsoft Azure, which allows users to run containers without managing servers. It provides hypervisor isolation for each container group to ensure containers run in isolation without sharing a kernel.
AWS Fargate: AWS Fargate is the service offered by Amazon Web Services, providing serverless compute for containers. It runs containers on Amazon Elastic Container Service (ECS) and Amazon Elastic Kubernetes Service (EKS) services.
Fission: Fission is an open-source project from Platform9, which provides a serverless Function-as-a-Service (FaaS) framework on Kubernetes.
Fn Project: Fn Project is an open-source container-native serverless platform that runs on any platform, local or cloud.
Virtual Kubelet: Virtual Kubelet connects Kubernetes to other APIs and masquerades them as Kubernetes nodes. These other APIs include ACI, Fargate, and IoT Edge.
Knative: Kubernetes-based platform to deploy and manage modern serverless workloads. Knative Features:
Serving: Run serverless containers on Kubernetes with ease. Knative takes care of the details of networking, autoscaling (even to zero), and revision tracking. You just have to focus on your core logic.
Eventing: Universal subscription, delivery, and management of events. Build modern apps by attaching compute to a data stream with declarative event connectivity and a developer-friendly object model.
OpenFaaS: is an open-source project that aims to simplify functions and code deployment directly to Kubernetes, OpenShift, or Docker Swarm.
Distributed Tracing
Organizations are adopting microservices for agility, easy deployment, scaling, etc. However, with many services working together, sometimes it becomes difficult to pinpoint the root cause of latency issues or unexpected behaviors. To overcome such situations, we would need to instrument the behavior of each participating service in our microservices-based application. After collecting and combining the instrumented data from each participating service, we should gain visibility of the entire system. This is generally referred to as distributed tracing.
OpenTelemetry: An observability framework for cloud-native software. OpenTelemetry is a collection of tools, APIs, and SDKs to the instrument, generate, collect, and export telemetry data (metrics, logs, and traces) for analysis to understand the software’s performance and behavior.
In general, a trace represents the details about a transaction, like how much time it took to call a specific function. In OpenTracing, a trace is referred to by the directed acyclic graph (DAG) of spans. Each span can be referred to as a timed operation between contiguous segments of work.
Using OpenTracing, we collect tracing spans for our services and then forward them to different tracers. Tracers are then used to monitor and troubleshoot microservices-based applications. Supported tracers for OpenTracing include Jaeger, LightStep, Instana, Elastic APM, Wavefront.
Hosting Providers: GitHub and More
There are other sites that offer similar services, including:
GitHub Repositories - Types
Private Repositories: Only selected collaborators can see the repository, or clone it (make a local copy), or download its contents in a variety of forms. The owner must specifically authorize each collaborator.
Public Repositories: Anyone given the proper link, such as
https:/github.com/an-account/a-repo, can copy, clone or fork the repository, or download its contents. However, unless the owner authorizes them as a collaborator, one does not have permission to upload or make modifications.
Advanced Git Interfaces: Gerrit
Git has well-established methods of workflow. It is pretty flexible and projects can choose quite different approaches, but it is always based on a cycle of:
Make changes in the code, probably in a development branch.
Commit those changes to the branch; there may be one or more changes (patches) per commit.
Publish those changes through a push or a pull request.
The changes will be reviewed and merged if necessary or sent back for further work.
Gerrit is built completely on Git, but it adds another layer of code review before changes are committed to the authoritative master repository. This review is likely to be done by multiple contributors rather than just one powerful maintainer. While such a workflow is not exactly new (most projects have multiple reviewers with some structure for who makes the ultimate decisions) the Gerrit architecture is designed to formalize this procedure.
Gerrit introduces a reviewing layer that lies between the contributors and the upstream repository.
Contributors submit their work (one change per submission is best) to the reviewing layer.
Contributors pull the latest upstream changes from the upstream layer.
Reviewers one the ones who submit work to the upstream layer.
The reviewers evaluate pending changes and discuss them. According to project governing procedures they can grant approval and submit upstream, or they can reject or request modifications.
Gerrit also records comments about each pending request and preserve them in a record which can be consulted at any time to provide documentation about why and how modifications were made.